UMLS Concepts are connected to each other by relationships. Conceptually, this structure is a large directed graph with 2.8M nodes and 51.7M relationships. Using a graph database such as Neo4j makes a lot of sense because we can use Neo4j's native query interface, the Cypher query language, to query this data - as a result we have an almost invisible user interface that is infinitely extensible (limited only by Cypher's own capabilities). In this post, I describe my use of Cypher (via Scala, using Neo4j's Java REST API) to build some navigational services to my UMLS based taxonomy.
As I mentioned last week, I loaded up the UMLS concept and relationship data using the batch-import tool. I realized after I did so that I would like an extra semantic codes field in my concept data, and that I would like to get rid of loops in my relationship data. So I downloaded the data from the UMLS database again using the following SQL calls.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | mysql> select c.CUI, c.STR, s.TUI
-> from MRCONSO c, MRSTY s
-> where c.LAT = 'ENG'
-> and c.CUI = s.CUI
-> into outfile '/tmp/cuistr.csv'
-> fields terminated by '\t'
-> lines terminated by '\n';
Query OK, 8801853 rows affected (7 min 55.23 sec)
mysql> select CUI1, CUI2, RELA from MRREL
-> where CUI1 != CUI2
-> into outfile "/tmp/cuirel.csv"
-> fields terminated by "\t"
-> lines terminated by "\n";
Query OK, 51737092 rows affected (1 min 36.94 sec)
|
I then ran a slightly modified version of the syns_aggregator_job.py to roll up synonyms as well as semantic types by CUI (resulting in a record represented by the case class Concept in the code below). Since the rels_filter_job.py was unnecessary, I didn't run it this time. I then added the headers as described in my previous post and reran the batch-import tool.
My objective was to implement four navigational services that are currently used with our memory based taxonomy front end. For each one I first tried out the Cypher query in the Neo4j shell to make sure it worked, then I implemented the service as a method in a Scala class as shown below. This blog post helped me to figure out how to use the Neo4j Java REST API.
The services implemented provide functionality to get a concept by its CUI, to list the unique outgoing relationships from a CUI, to list the CUIs of related concepts for a given CUI and relationship and to find the path between two concepts specified by their CUIs. All the services use the Lucene index "concepts" that was created during the batch import process to look up nodes by CUI rather than the internal Neo4j nodeID.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 | // Source: src/main/scala/com/mycompany/scalcium/umls/NeoClient.scala
package com.mycompany.scalcium.umls
import org.neo4j.rest.graphdb.RestAPIFacade
import org.neo4j.rest.graphdb.query.RestCypherQueryEngine
import spray.json._
import DefaultJsonProtocol._
import scala.collection.JavaConversions._
class NeoClient {
val db = new RestAPIFacade("http://localhost:7474/db/data")
val engine = new RestCypherQueryEngine(db)
//////////////////// services ///////////////////////////
def getConceptByCui(cui: String): Option[Concept] = {
val result = engine.query("""
start n=node:concepts(cui={cui}) match (n)
return n.cui, n.syns, n.stys""",
Map(("cui", cui)))
val iter = result.iterator()
if (iter.hasNext()) {
val row = iter.next()
val cui = row("n.cui").asInstanceOf[String]
val syns = row("n.syns").asInstanceOf[String]
.replaceAll("'", "\"")
.asJson
.convertTo[List[String]]
val stys = row("n.stys").asInstanceOf[String]
.replaceAll("'", "\"")
.asJson
.convertTo[List[String]]
Some(Concept(cui, syns, stys))
} else None
}
def listRelationships(cui: String): List[String] = {
val result = engine.query("""
start m=node:concepts(cui={cui})
match (m)-[r]->(n)
return distinct type(r) as rel""",
Map(("cui", cui)))
result.iterator()
.map(row => row("rel").asInstanceOf[String])
.toList
}
def listRelatedConcepts(cui: String, rel: String):
List[String] = {
val result = engine.query("""
start m=node:concepts(cui={cui})
match (m)-[%s]->(n)
return n.cui""".format(rel),
Map(("cui", cui)))
result.iterator()
.map(row => row("n.cui").asInstanceOf[String])
.toList
}
def shortestPath(cui1: String, cui2: String,
maxLen: Int): (List[String], List[String], Int) = {
val result = engine.query("""
start m=node:concepts(cui={cui1}),
n=node:concepts(cui={cui2})
match p = shortestPath(m-[*..%d]->n)
return p""".format(maxLen),
Map(("cui1", cui1), ("cui2", cui2)))
val iter = result.iterator()
if (iter.hasNext()) {
val row = iter.next()
row("p") match {
case (nvps: java.util.LinkedHashMap[String,_]) => {
val nodelist = nvps("nodes") match {
case (nodes: java.util.ArrayList[_]) =>
nodes.map(url =>
getCuiByUrl(url.asInstanceOf[String]))
.toList
.flatten
case _ => List()
}
val rellist = nvps("relationships") match {
case (rels: java.util.ArrayList[_]) =>
rels.map(url =>
getRelNameByUrl(url.asInstanceOf[String]))
.toList
.flatten
case _ => List()
}
val length = nvps("length").asInstanceOf[Int]
return (nodelist, rellist, length)
}
}
}
return (List(), List(), -1)
}
//////////////// methods for internal use //////////////////
def getConceptById(id: Int): Option[Concept] = {
getCuiById(id) match {
case Some(cui: String) => getConceptByCui(cui)
case None => None
}
}
def getCuiByUrl(url: String): Option[String] =
getCuiById(getIdFromUrl(url))
def getCuiById(id: Int): Option[String] = {
val result = engine.query("""
start n=node(%d) return n.cui limit 1"""
.format(id), Map[String,Object]())
val iter = result.iterator()
if (iter.hasNext()) {
val row = iter.next()
Some(row("n.cui").asInstanceOf[String])
} else None
}
def getRelNameByUrl(url: String): Option[String] =
getRelNameById(getIdFromUrl(url))
def getRelNameById(id: Int): Option[String] = {
val result = engine.query("""
start r=relationship(%d) return type(r) as rt limit 1"""
.format(id), Map[String,Object]())
val iter = result.iterator()
if (iter.hasNext()) {
val row = iter.next()
Some(row("rt").asInstanceOf[String])
} else None
}
def getIdFromUrl(url: String): Int =
url.substring(url.lastIndexOf('/') + 1).toInt
}
case class Concept(val cui: String,
val syns: List[String],
val stys: List[String])
|
I had to add the following dependencies to my build.sbt to get this to compile and run.
1 2 3 4 5 6 7 8 9 10 11 12 | ...
resolvers ++= Seq(
"spray" at "https://repo.spray.io/",
"Neo4j-Contrib" at "http://m2.neo4j.org/content/groups/everything"
)
libraryDependencies ++= Seq(
...
"org.neo4j" % "neo4j" % "1.9.6",
"org.neo4j" % "neo4j-rest-graphdb" % "1.9",
"io.spray" %% "spray-json" % "1.2.5"
)
|
To execute the services, I used the JUnit test shown below. Results are inlined with the code to make it easy to see.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 | // Source: src/test/scala/com/mycompany/scalcium/umls/NeoClientTest.scala
package com.mycompany.scalcium.umls
import org.junit.Test
import org.junit.Assert
class NeoClientTest {
val client = new NeoClient()
@Test
def testGetCuiById(): Unit = {
val cui = client.getCuiById(5911)
Console.println("cui=" + cui)
Assert.assertNotNull(cui)
}
/*
cui=Some(C0011847)
*/
@Test
def testGetConceptById(): Unit = {
client.getConceptById(5911) match {
case Some(concept) => {
printConcept(concept)
Assert.assertNotNull(concept)
}
case None => Assert.fail("No concept found?")
}
}
/*
==== Concept (cui=C0011847) ====
name: Diabetes
#-syns: 0
sty-codes: T047
*/
@Test
def testGetConceptByCui(): Unit = {
client.getConceptByCui("C0027051") match {
case Some(concept) => {
printConcept(concept)
Assert.assertEquals(concept.cui, "C0027051")
Assert.assertEquals(concept.syns.size, 57)
Assert.assertEquals(concept.stys.size, 1)
}
case None => Assert.fail("No concept found?")
}
}
/*
==== Concept (cui=C0027051) ====
name: Infarctions (Myocardial)
#-syns: 56
sty-codes: T047
*/
@Test
def testListRelationships(): Unit = {
val rels = client.listRelationships("C0027051")
Console.println("relations:" + rels)
Assert.assertNotNull(rels)
Assert.assertEquals(34, rels.size)
}
/*
relations: List(classified_as, classifies, isa, associated_morphology_of, \
finding_site_of, has_associated_finding, occurs_after, inverse_isa, \
has_manifestation, subset_includes_concept, is_associated_anatomic_site_of, \
gene_associated_with_disease, used_for, mapped_from, has_member, ...)
*/
@Test
def testListRelatedConcepts(): Unit = {
val relcs = client.listRelatedConcepts(
"C0027051", ":drug_contraindicated_for")
Console.println("related concepts:" + relcs)
Assert.assertNotNull(relcs)
Assert.assertEquals(389, relcs.size)
}
/*
related concepts:List(C2683677, C2683676, C2683677, C2683678, \
C0788742, C0788743, C0938788, C0788741, C1827483, C1827483, \
C0978677, C0978677, C2912075, C1177994, C1177993, ...)
*/
@Test
def testShortestPath(): Unit = {
val shortestPath = client.shortestPath("C0027051", "C0011847", 5)
Console.println("nodelist=" + shortestPath._1)
Assert.assertNotNull(shortestPath._1)
Assert.assertEquals(3, shortestPath._1.size)
Console.println("rellist=" + shortestPath._2)
Assert.assertNotNull(shortestPath._2)
Assert.assertEquals(2, shortestPath._2.size)
Assert.assertEquals(2, shortestPath._3)
}
/*
nodelist=List(C0027051, C0935495, C0011847)
rellist=List(has_member, member_of)
cui=Some(C0011847)
*/
def printConcept(concept: Concept): Unit = {
Console.println(
"==== Concept (cui=%s) ====".format(concept.cui))
Console.println("name: %s".format(concept.syns.head))
Console.println("#-syns: %d".format(concept.syns.tail.size))
Console.println("sty-codes: %s".format(concept.stys.mkString(", ")))
}
}
|
Cypher looks a bit different than most high level query languages (at least it looked different to me), but there are good resources for learning Cypher such as this one. Cypher makes accessing the data in the graph really simple. It also opens the door for some graph based analytics in the future. Also scaling wise, since the taxonomy is read only (the data is maintained via a CRUD webapp in a RDBMS and exported periodically), the REST API enables us to balance load across multiple replica graph servers.
Update: 2014-03-09: I spoke about doing graph analytics in my post. One of the basic things one can do to understand a graph is to find the degree distribution. Cypher provides queries that do this, such as this one:
1 2 3 4 | neo4j-sh (0)$ start n=node(*)
> match (n)-[r]->m
> return n.cui, count(r) as degree
> order by degree desc;
|
I tried it, but it just hung forever (I waited about 10 mins before breaking it). Not surprising, since we are trying to sort the entire database by a computed field. So I decided to dump out the degrees for all nodes using code like below and do the collecting and sorting outside Neo4j.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | def degreeDistrib(inDegree: Boolean, outfile: File): Unit = {
val writer = new PrintWriter(new FileWriter(outfile))
val cuilist = engine.query("""
start n=node(*) return n.cui""",
Map[String,Object]())
var numProcessed = 0
val x = cuilist.iterator().foreach(row => {
numProcessed += 1
if (numProcessed % 1000 == 0)
Console.println("Processed %d nodes".format(numProcessed))
val cui = row("n.cui")
val larrow = if (inDegree) "<-" else "-"
val rarrow = if (inDegree) "-" else "->"
val countQuery = engine.query("""
start n=node:concepts(cui={cui})
match (n)%s[r]%s(m)
return n.cui, count(r) as nrels"""
.format(larrow, rarrow),
Map(("cui", cui)))
val iter = countQuery.iterator()
if (iter.hasNext()) {
val crow = iter.next()
writer.println("%s\t%s".format(crow("n.cui"), crow("nrels")))
}
})
writer.close()
writer.flush()
}
|
Then plot the data generated using Python and matplotlib.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import matplotlib.pyplot as plt
import numpy as np
import math
fin = open("dd_out.csv", 'rb')
xs = []
for line in fin:
line = line.strip()
xs.append(math.log(int(line.split()[1])))
fin.close()
hist, bins = np.histogram(xs, bins=50)
width = 0.7 * (bins[1] - bins[0])
center = (bins[:-1] + bins[1:]) / 2
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_title("Log(Out-Degree) Distribution")
ax.set_xlabel("Log(Out-Degree)")
ax.set_ylabel("#-concepts")
ax.bar(center, hist, align="center", width=width)
plt.show()
|

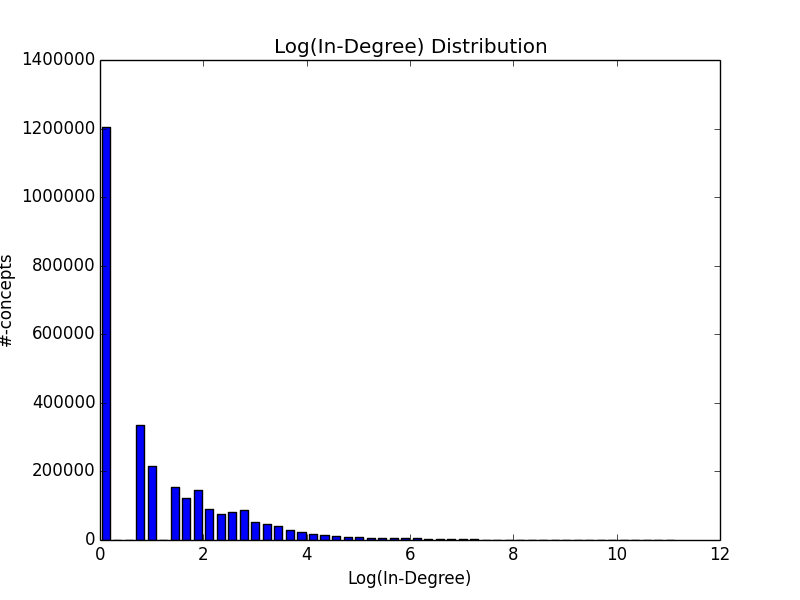
Identifying nodes with high cardinality is another way to understand a graph dataset, and we can do this as well with a few lines of Python.
1 2 3 4 5 6 7 8 9 10 11 12 | from operator import itemgetter
fin = open("dd_in.csv", 'rb')
xs = []
for line in fin:
line = line.strip()
cui, degree = line.split("\t")
xs.append((cui, int(degree)))
fin.close()
xss = sorted(xs, key=itemgetter(1), reverse=True)
for pair in xss[0:10]:
print "\t".join([pair[0], str(pair[1])])
|
The top 10 nodes by out-degree and their corresponding out-degrees are shown below:
1 2 3 4 5 6 7 8 9 10 11 12 | CUI Out-Degree
===========================
C1442880 69031
C3160963 65817
C1261322 58469
C0677612 54725
C1123023 47823
C0728940 44444
C2628818 41235
C0021368 40720
C1964004 37755
C0000768 37044
|
And the top 10 nodes by in-degree:
1 2 3 4 5 6 7 8 9 10 11 12 | CUI In-Degree
===========================
C1442880 69031
C3160963 65817
C1261322 58469
C0677612 54725
C1123023 47823
C0728940 44444
C2628818 41235
C0021368 40720
C1964004 37755
C0000768 37044
|
We can use similar strategies to answer application level analytics type questions as well.
As always, love the posts. Would you mind posting the "slightly modified" aggregator?
ReplyDeleteBest, JG
Thanks JG. Don't have the aggregator handy, but the original is here and it splits up the original record (CUI, descr) and groups by CUI. The modified one will take in (CUI, descr, TUI), in the mapper and maintain two sets in the reducer, one for descr and one for TUI. Once it goes through all the values, it will attach the two lists to the record. Something like this (redoing because blogger comments break whitespace indentation and we need this here...)
ReplyDeleteclass SynsAggregatorJob1(MRJob):
....def mapper(self, key, value):
........(cui, descr, tui) = value.split("\t")
........yield cui, "::".join([tui, descr])
....def reducer(self, key, values):
........uniqSyns = set()
........uniqStys = set()
........for value in values:
............sty, syn = value.split("::")
............uniqSyns.add(syn)
............uniqStys.add(sty)
........print("%s\t%s\t%s" % (key, list(uniqSyns), list(uniqStys)))
Thanks for the previous reply!
ReplyDeleteI wonder, did you run into the following: https://github.com/jexp/batch-import/issues/114
It started out as a string error, then I specified explicitly tab delineation and it became a null pointer error... I know you did this a year ago so it could be version differences, but thorough searching didn't reveal an answer and Im a bit stumped.
Nope, don't recall seeing this error, sorry. From the issue description (and refreshing my memory from the previous blog post), seems like you are doing exactly what I was doing.
ReplyDeleteThanks for looking it over. Ill delve in with a debugger and see whats going on or maybe Ill hear back from the maintainer. In either case if I get a solution Ill post back here for others.
ReplyDelete