ETL (Extract, Transform, Load) has traditionally been the domain of data warehousing practitioners, but it can be applied to any process or set of processes that load data into databases. Data is the lifeblood of any organization. However, data by itself is not too interesting - what is interesting is the information that the data can be processed into. Many enterprise systems dedicate a significant chunk of their functionality and resources to developing programs and scripts that transform and migrate data from one form to another, so the downstream module can present it in a manner more intuitive to their clients.
Writing data transformation routines may be pervasive, but the actual transformation code is generally not very challenging. More challenging is splitting up the transformation into multiple threads and running them in parallel, since ETL jobs usually work with large data sets, and we want the job to complete in a reasonable time. Business application developers generally don't do multithreaded programming too well, mainly because they don't do it often enough. Furthermore, the transformation business logic is inside the application code, which means it cannot be sanity checked by the business person whose needs drove the transformation in the first place.
I heard about Kettle, an open source ETL Tool, from a colleague at a previous job, where he was using it to automate data transformations to push out denormalized versions of data from backend databases to frontend databases. Unfortunately, I never got a chance to use it at work, but it remained on my ToDo list as something I wanted to learn for later. Kettle started as a project by a single developer, but has since been acquired by Pentaho who sell and support a suite of open source Business Intelligence tools, of which Kettle is one, under a dual open-source/commercial license similar to MySQL.
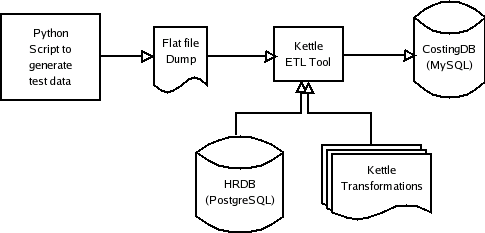
Early in my career, I worked for the MIS group of a factory that manufactured switchboards. It occured to me that one of the processes for generating monthly factory-wide input costs would be a good candidate to convert to Kettle and understand its functionality. Part of the input costs for the factory for the month were the sum of the actual dollar amount paid out to workers. This was governed by the worker's hourly rate and the number of hours worked. The number of hours were derived from the times recorded when the worker signed in and out of the factory. The values are reported by department. The figure below shows the flow.

To replicate the process, I created a flat file for 5 employees in 2 departments (Electrical and Mechanical) which contained in and out times for these employees over a 30 day period. The original databases involved were dBase-IV and Informix with migration scripts written with Clipper and Informix-4GL, the ones in my case study were PostgreSQL and MySQL. A data flow diagram for the Kettle based solution is shown below:
The input file dump looks like this:
1 2 3 4 5 | 1000015 I 2006-08-01 08:07:00 1154444820
2000024 I 2006-08-01 08:09:00 1154444940
1000015 O 2006-08-01 16:05:00 1154473500
2000024 O 2006-08-01 16:08:00 1154473680
...
|
The tables involved in the HRDB PostgreSQL table look like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | hrdb=> \d employee
Table "public.employee"
Column | Type | Modifiers
---------------+------------------------+-----------
emp_id | integer |
dept_id | integer |
emp_name | character varying(255) |
rate_per_hour | numeric(8,2) |
hrdb=> \d timecard
Table "public.timecard"
Column | Type | Modifiers
----------+---------------+-----------
emp_id | integer | not null
tc_date | character(10) | not null
time_in | integer |
time_out | integer |
|
And the MySQL table that is populated as a result of the transformations looks like this:
1 2 3 4 5 6 7 | mysql> desc input_cost;
+------------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+---------------+------+-----+---------+-------+
| dept_id | int(11) | | | 0 | |
| input_cost | decimal(12,2) | YES | | NULL | |
+------------+---------------+------+-----+---------+-------+
|
Kettle comes with four main components - Spoon, Pan, Chef and Kitchen. Spoon is a GUI editor for building data transformations. Pan is a command line tool for running a transformation created with Spoon. Chef is a GUI for building up jobs, which are a set of transformations that should work together, and Kitchen is again a command line tool to run jobs built with Chef.
I balked initially at having to use a GUI to design transformations. I would have preferred a scripting language or some sort of XML configuration to do this, but I guess developers have traditionally not been the target market for ETL tools. And I guess the objective of using Kettle is to not do programming for data transformations, and to a certain extent, scripting is programming. Anyway, using Spoon was pretty straightforward, and I was able to generate three transformations which could be applied to my flat file dump in sequence to produce two rows in the CostingDB MySQL table.
Each Spoon Transformation produces as output a .ktr XML file. It can also write the transformation metadata to a database repository (the recommended option). The first transformation reads the flat file, choosing rows with the "I" flag set (for incoming timecard entry), and inserts it into the HRDB.timecard table. The second transformation reads the flat file a second time, this time choosing rows with the "O" flag set (for outgoing timecard entry) and updates the time_out column in the timecard table. The reason we have two separate transformations instead of having two streams from the filter is because the two streams are going to be multi-threaded and there is no guarantee that an insert would complete before the corresponding update is applied.
|
|
|
|
|
The third transformation reads the HRDB.timecard table, calculates worked hours per employee over the given time period, aggregates the worked hours per employee, applies the employee's per hour rate from the HRDB.employee table to get the dollar value to be paid out, then groups and aggregates the dollar values over department, then inserts the two rows into the MySQL CostingDB table.
|
|
You can run the transformations individually through Spoon using the "Run" icon. Alternatively, you can run them through the Pan tool. Here is a Pan script that runs the entire transformation:
1 2 3 4 5 6 7 | #!/bin/bash
KETTLE_HOME=/path/to/your/kettle/installation/here
cd $KETTLE_HOME
./pan.sh -file=usr/costing/extract_in_times.ktr
./pan.sh -file=usr/costing/extract_out_times.ktr
./pan.sh -file=usr/costing/aggregate_worked_hrs.ktr
cd -
|
Alternatively, you could use Chef GUI Tool to build up this job graphically. Chef offers some other features such as modules which do FTP, send email and so on. The job is shown graphically below, along with the generated .kjb file.

|
Finally, you can run more than one job, schedule them and so on using Kitchen. Frankly, I dont see much reason to use Chef and Kitchen, since you can just write Pan scripts and schedule them via cron, but I guess the Kettle team put them in there for completeness.
My conclusion is that Spoon is fairly powerful and provides very powerful plumbing to design and run ETL jobs. I still dont like the fact that the only programming interface is a GUI, but I dont have any concrete suggestions for a scripting interface. For those whose needs are not met by the standard components provided by Spoon, there is the Injector component which can be backed by user-supplied Java code, so Kettle also provides a hook for extensibility.















2 comments (moderated to prevent spam):
Hi Stuart,
I am not really an ETL expert, I heard good things about Kettle from a colleague who used it extensively at work. As you will see from my article, this was a toy project I did to understand how to apply Kettle to a real-life situation, should it happen in the future. My conclusion was that it currently offers many ways to build a data workflow and is quite flexible, but there are not too many extension points should it become necessary. However, it /is/ open-source, so it should not be too hard to peek at the source and add customizations.
As for my interest in starting a discussion, unfortunately my job at a startup currently does not leave me with too much bandwidth to do any real (deadline driven) work outside of work. If you like, I can talk to my colleague (who introduced me to Kettle, and who is probably more suited to the work you speak of, both in terms of skills and interests) and see if he may be interested. If you want, you are welcome to contact me privately via LinkedIn.
-sujit
Extention points:
- A plugin system where you can write your own steps & job entries.
- Javascript with unlimited access to your system
- piping text file output to 3rd party software (upcoming 2.4.0 release)
Matt
Post a Comment