One of the assignments at the Introduction to Data Science course at Coursera is to design visualizations using Tableau for the FAA Bird Strike dataset. One big problem (for me) is that Tableau is Windows only, and I have a Mac. So before I used my wife's Windows PC to complete the assignment, I decided to try doing the visualizations in R as a way to understand the data.
I have used R in two previous Coursera courses, namely Computing for Data Analysis and Data Analysis, but I don't get enough practice with R since I much prefer using Python. I guess part of the reason is my familiarity with Python, but I feel that Python as a language is more well-designed and easier to use than R. However, I have been meaning to start using R for a while, and this seemed to be a good opportunity, since graphics are easier with R than with Python+Matplotlib.
The data is provided as part of a Tableau workbook, so to extract the data, I downloaded Tableau on my wife's PC, load up the workbook and export the data to an Excel worksheet, which I then converted to a CSV file using Open Office on my Mac. Now we are ready to answer the questions posed.
How large is our data set?
1 2 | df <- read.csv("/path/to/BirdStrikes.csv");
print(dim(df));
|
This tells us that our data has 10,000 rows and 30 columns. Note that this is a truncated version of the full Bird Strikes data. I could have downloaded the original from the website but it comes as an MS-Access database and I could not get Open Office to read it.
When strikes happen, from where do they originate?
Our data is US only, and we have a Origin.State field which contains the name of the state where the flight originated. For our visualization, we use a map of the USA with the states colored with blue shades to indicate the number of strikes flights originating from them get.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | library(maps)
library(RColorBrewer)
bsdf <- as.data.frame(table(df.clean$Origin.State))
bsdf$Var1 = tolower(bsdf$Var1)
maxfreq <- max(bsdf$Freq)
usa <- map("state", fill=FALSE)
palette <- brewer.pal(9, "Blues")
name.idxs <- match.map(usa, bsdf$Var1, exact=FALSE)
print(name.idx)
freqs <- as.array(bsdf$Freq)
colors <- c()
for (i in 1:length(usa$names)) {
stname <- strsplit(usa$names[i], ':')[[1]][1]
freq <- bsdf[bsdf$Var1 == stname, ]$Freq
if (length(freq) > 0) {
col.idx <- round(9 * freq / maxfreq)
if (col.idx == 0) col.idx = 1
color <- palette[col.idx]
colors <- cbind(colors, color)
print(paste(usa$names[i], stname, freq, col.idx, color))
} else {
color <- palette[1]
colors <- cbind(colors, color)
print(paste(usa$names[i], stname, freq, col.idx, color))
}
}
usa <- map("state", fill=TRUE, col=colors)
title("States by Strike Count")
leg.txt <- c("Low", "Avg", "High")
leg.cols <- c(palette[1], palette[5], palette[9])
legend("bottomright", horiz=FALSE, leg.txt, fill=leg.cols)
|
The image generated by the above code looks like this...

What are the top states in which strikes occur?
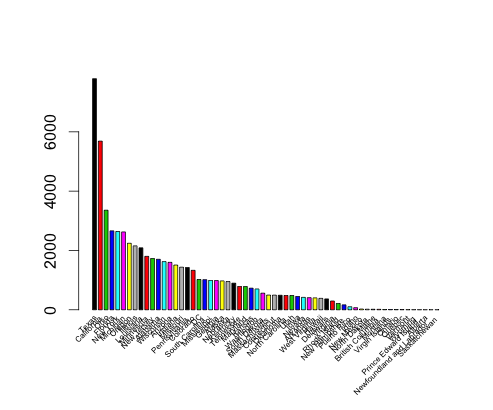
Although the shaded map is good for an instant look (and it tells me that my home state of California is the top state for bird strikes, followed by Texas, it does not give a quantiative feel for the data. For that we need a bar chart...
1 2 3 4 5 6 7 8 | # calculate counts of bird hits by Origin.State and sort by count desc
bsdf <- as.data.frame(table(df.clean$Origin.State))
bsdf.sorted <- bsdf[with(bsdf, order(-Freq)), ]
bar <- barplot(height=bsdf.sorted$Freq, horiz=FALSE, beside=TRUE,
width=c(2,2), space=0.5, xaxt="n",
col=palette())
text(bar, par("usr")[3], labels=bsdf.sorted$Var1, srt=45,
adj=c(1.1, 1.1), xpd=TRUE, cex=0.5)
|
As you can see, California still leads and Texas follows close behind, although the names of states are a bit hard to read, even with the 45 degree rotation.

We may also want to find out which states end up paying the most for these bird hits. For this we simply calculate the sum of costs (given by the Cost..Total.. column) by Origin.State.
1 2 3 4 5 6 7 8 9 10 | # calculate sum of costs incurred by Origin.State and sort by cost desc
cidf <- aggregate(as.numeric(Cost..Total..) ~ Origin.State,
data=df.clean, FUN="sum")
names(cidf) <- c("state", "cost")
cidf.sorted <- cidf[with(cidf, order(-cost)), ]
bar2 <- barplot(height=cidf.sorted$cost, horiz=FALSE, beside=TRUE,
width=c(2,2), space=0.5, xaxt="n",
col=palette())
text(bar2, par("usr")[3], labels=cidf.sorted$state, srt=45,
adj=c(1.1, 1.1), xpd=TRUE, cex=0.5)
|
and it turns out that Texas incurs the highest cost of bird hits...
Has there been a change in strikes over time?
We have data from January 2000 to August 2001, so we can draw a simple line chart to visualize the change of bird hits over time.
1 2 3 4 5 6 7 8 9 10 11 | # find counts by flight date
fdds <- as.data.frame(table(df$FlightDate))
fdds$Var1 <- as.Date(fdds$Var1, format="%m/%d/%Y %H:%M")
fdds.sorted <- fdds[with(fdds, order(Var1)), ]
plot(fdds.sorted$Var1, fdds.sorted$Freq, type="l",
xlab="Flight Date", ylab="Bird Strikes",
main="Bird Strikes (daily)")
# compute trend line and place
model <- lm(fdds.sorted$Freq ~ fdds.sorted$Var1)
abline(model, col="red", lwd=4)
|
This shows us a seasonal trend that peaks around fall each year, probably at around the time birds migrate south for the winter. As shown by the thick red line (fitted using a linear model), bird strikes appear to be trending upwards.

Use the "Effect: Impact to Flight" dimension to investigate.
Even though we know that the number of strikes are increasing, its not clear as to whether this is because we are getting better with reporting or if aviation safety is getting worse. In other words, how many of these strikes result in engine failure or some other serious effect? For this, we use the "Effect..Impact.to.flight" column. It has 6 categorical values, so our initial visualization is to do a scatter plot over time.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | # preprocess and sort data by flight date
df$FlightDate <- as.numeric(
as.Date(df$FlightDate, format="%m/%d/%Y %H:%M") -
as.Date("1970-01-01", format="%Y-%m-%d"))
df$Effect..Impact.to.flight <- as.factor(df$Effect..Impact.to.flight)
df.sorted <- df[with(df, order(FlightDate)), ]
# find limits for graphing
ylim.min <- min(as.numeric(df.sorted$Effect..Impact.to.flight))
ylim.max <- max(as.numeric(df.sorted$Effect..Impact.to.flight))
xlim.min <- min(df$FlightDate)
xlim.max <- max(df$FlightDate)
xlim.cent <- (xlim.min + xlim.max) / 2
# colors for graphing
colors <- palette()
idf <- as.data.frame(table(df.sorted$Effect..Impact.to.flight))
i <- 1
leg.txt <- c()
leg.cols <- c()
for (impact.str in idf$Var1) {
df.subset <- df.sorted[df.sorted$Effect..Impact.to.flight == impact.str, ]
if (i == 1) {
print(paste("in plot:", impact.str, colors[i]))
plot(df.subset$FlightDate,
df.subset$Effect..Impact.to.flight,
col=colors[i], xaxt="n", yaxt="n",
xlab="Time", ylab="Impact Type",
ylim=c(ylim.min, ylim.max), xlim=c(xlim.min, xlim.max),
main="Impact Types over Time")
} else {
print(paste("in line:", impact.str, colors[i]))
points(df.subset$FlightDate,
df.subset$Effect..Impact.to.flight,
col=colors[i])
}
leg.cols <- cbind(leg.cols, colors[i])
leg.txt <- cbind(leg.txt, impact.str)
i <- i + 1
}
x.at <- c(xlim.min, xlim.cent, xlim.max)
x.labels <- as.Date("1970-01-01") + x.at
axis(1, at=x.at, labels=x.labels, las=0)
axis(2, at=c(1,2,3,4,5,6), labels=c("UK", "AT", "ES", "NO", "OT", "PL"),
las=2, cex=0.5)
|
Of these, the UK (Unknown), NO (None) and OT (Other) values do not convey any information, except that they are perhaps too minor to document. The interesting categories are AT (Aborted Take-off) in red, ES (Engine shutdown) in green and PL (Precautionary Landing) in magenta. As we can see, Engine Shutdown cases are thankfully not too many to begin with and are actually becoming a thing of the past. Aborted Takeoffs are rising, but not as much as Precautionary Landings.

A better visualization is line charts. As before, we roll up the data into months for each impact type. We remove the Unknown, None and Other impact type values since they don't convey any useful information (and it messes up our scales as well :-)).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | # roll up by YYYYMM, so we convert the FlightDate to that
df$FlightDate <- as.numeric(format(as.Date(df$FlightDate,
format="%m/%d/%Y %H:%M"), "%Y%m"))
# subset and roll up counts for each impact type
impact.types <- as.data.frame(table(df$Effect..Impact.to.flight))
# we visually figure out the ymin and ymax values for all impact types
ylimits <- c(0, 60)
i <- 1
colors <- palette()
for (impact.type in impact.types$Var1) {
if (nchar(impact.type) > 0 &
impact.type != "None" &
impact.type != "Other") {
df.subset <- df[as.character(df$Effect..Impact.to.flight) == impact.type, ]
df.count <- as.data.frame(table(df.subset$FlightDate))
if (i == 1) {
print(paste("in plot:", impact.type, colors[i],
min(df.count$Freq), max(df.count$Freq)))
plot(as.numeric(df.count$Var1),
df.count$Freq, type="l",
col=colors[i], xaxt="n",
xlab="Time", ylab="#-impacts",
ylim=ylimits,
main="Impact Types over Time")
} else {
print(paste("in line:", impact.type, colors[i],
min(df.count$Freq), max(df.count$Freq)))
lines(as.numeric(df.count$Var1),
df.count$Freq,
col=colors[i])
}
i <- i + 1
}
}
x.at <- c(1, 20)
x.labels <- c("2000-01", "2001-08")
axis(1, at=x.at, labels=x.labels, las=0)
legend("topright", c("AT", "ES", "PL"),
fill=c(colors[1], colors[2], colors[3]), horiz=TRUE)
|
The resulting graph confirms our observation that Engine Shutdown is no longer an issue, and that Aborted Takeoff and Precautionary Landings are on the decline as well.

How does it compare to using Tableau?
Well, to give Tableau due credit, its very nice once you get the hang of it. I had trouble because I could not find the sidebar menu (which is needed to do almost anything, and which for reasons unknown was turned off by default - I had to go into the Windows tab and turn it on. Once I got that, I was able to complete the assignment - basically the answers to the questions posed above plus one question you had to think up for yourself and answer it - in under an hour. In comparison, doing the same thing in R took me approximately 5-6 hours (although I am guessing that number will decrease as I become more fluent with R).
That said, Tableau is neither free nor multi-platform. It runs only on Windows, although that may change to include Linux and Mac users in the future. Second, I was on a teaser (but fully functional) version. So you need to like it enough to want to (or cajole your employer to) pay for it. For the moment, I think I will stick with R.















3 comments (moderated to prevent spam):
Hi sqiar, thank you for your comment, although it reads like borderline spam (apologies if it wasn't, perhaps you could say something relevant to the post next time?). I have allowed it because the link points to a consulting company in a space relevant to this post.
Hi Sujit,
How did you export data from the tableau file into excel?
Thanks, Kamal
Yes. The data was supplied in a (proprietary?) Tableau format, so to get to it, I had to download Tableau (my wife used a PC), download to Excel, then download to CSV.
Post a Comment