Some time back, I built a Topic Model with Gensim over a set of around 2000 Medical Transcriptions. The resulting model did not have very good separation, and wasn't very useful. One of the things I noticed at the time was that certain words which were relatively frequent across the corpus, such as "patient", "history", "normal", etc, were showing up with high p(Topic|Term) values across one or more topics. So one of the improvements I thought of making at the time was to generate corpus-specific stopwords (with high Document Frequency) and removing them from the input text.
An extension to the custom stopword removal idea was to use generated keywords from the text instead of the text itself. Fortunately, each document in the corpus has been hand-annotated with a set of keywords. I already had some code I had built for an earlier experiment on Keyword Extraction with KEA, so I trained KEA with a 10% split of the corpus and generated upto 40 keywords per document for the remaining 90%. I then used Gensim to build a Topic Model. This post describes the effort and the results.
Since the current effort builds on the experiments described in these two previous posts, I don't show the code that is already available in these posts. In any case, the Python code is here and the Scala code is here in two separate GitHub repositories. Here is what I did, I will describe each of these steps in more detail below.
- Split the MTS corpus (JSON format) into a 10/90 train/test split.
- Train KEA with 10% set, then use model to generate keywords on remaining 90%.
- Annotate the text of the full corpus against these keywords. Output is a set of documents containing only keywords.
- Build Bag-of-Keywords (BOK) model from these documents.
- Find Optimum Number of Topics.
- Build LDA Topic Model with Optimum Topics and Analyze.
Split MTS Corpus
This step is a pre-processing step to prepare the MTS data for KEA. We have a set of 2000+ JSON files, each file corresponding to a single patient encounter. Among the information contained in the file are the text content and keywords. We extract this into a directory structure that looks like this.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | .
|-- test
| |-- 0000.txt
| |-- 0001.txt
| | ...
| |-- 4816.txt
| `-- keys
| |-- 0000.key
| |-- 0001.key
| | ...
| `-- 4816.key
`-- train
|-- 0003.key
|-- 0003.txt
|-- 0021.key
|-- 0021.txt
| ...
|-- 4690.key
`-- 4690.txt
|
The .txt files contains the value of the text field and the .key files contain the keywords, one per line. The .txt and .key files are put into the same directory for the training set (because KEA expects them there). In case of the test set, the keys are put into a subdirectory called keys (since KEA will overwrite the .key files in the same directory). The code to do this is fairly straightforward, its shown below:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | # Source: src/topicmodel/kea_preprocess.py
import json
import os
import random
import shutil
JSONS_DIR = "/path/to/jsons"
KEA_TRAIN_DIR = "/path/to/train/dir"
KEA_TEST_DIR = "/path/to/test/dir"
shutil.rmtree(KEA_TRAIN_DIR)
shutil.rmtree(KEA_TEST_DIR)
os.mkdir(KEA_TRAIN_DIR)
os.mkdir(KEA_TEST_DIR)
os.mkdir(os.path.join(KEA_TEST_DIR, "keys"))
for filename in os.listdir(JSONS_DIR):
print "Converting %s..." % (filename)
fjson = open(os.path.join(JSONS_DIR, filename), 'rb')
data = json.load(fjson)
fjson.close()
basename = os.path.splitext(filename)[0]
# do a 10/90 split for training vs test
train = random.uniform(0, 1) <= 0.1
txtdir = KEA_TRAIN_DIR if train else KEA_TEST_DIR
ftxt = open(os.path.join(txtdir, basename + ".txt"), 'wb')
ftxt.write(data["text"].encode("utf-8"))
ftxt.close()
# write keywords
keydir = KEA_TRAIN_DIR if train else os.path.join(KEA_TEST_DIR, "keys")
fkey = open(os.path.join(keydir, basename + ".key"), 'wb')
keywords = data["keywords"]
for keyword in keywords:
fkey.write("%s\n" % (keyword.encode("utf-8")))
fkey.close()
|
Train KEA and Generate Keywords
This is done using code already described in a previous post. The only change I made was to increase the maximum number of keywords generated per document from 10 to 40. We train using the 10% set and generate keywords for the remaining 90%. In my previous experiments, I had found KEA to be remarkably resilient to training set size, so I did not have too much reservation about training it with 10% of the data. The test set already had 51,754 keywords assigned manually. After the keyword generation step, it had an additional 69,353 keywords. Combined, the number of unique keywords (single and multi-word) were 33,512. Contrast this with 987,620 words in the training set with 61,116 unique words. The code to combine the two lists is also quite simple, its here:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | # Source: src/topicmodel/keywords_merge.py
# -*- coding: utf-8 -*-
import nltk
import os
USER_KEYWORDS_DIR = "/path/to/testset/keys"
KEA_KEYWORDS_DIR = "/path/to/testset"
KEYWORDS_FILE = "/path/to/merged_keys.txt"
# Additional stopwords found by observing final wordclouds
CUSTOM_STOPWORDS = ["patient", "normal", "mg"]
def main():
# get set of english keywords from NLTK
stopwords = set(nltk.corpus.stopwords.words("english"))
# add own corpus-based stopwords based on high IDF words
for custom_stopword in CUSTOM_STOPWORDS:
stopwords.add(custom_stopword)
keywords = set()
for f in os.listdir(USER_KEYWORDS_DIR):
# only select the .key files
if f.endswith(".txt") or f == "keys":
continue
fusr = open(os.path.join(USER_KEYWORDS_DIR, f), 'rb')
for line in fusr:
line = line.strip().lower()
if line in keywords:
continue
keywords.add(line)
fusr.close()
for f in os.listdir(KEA_KEYWORDS_DIR):
fkea = open(os.path.join(KEA_KEYWORDS_DIR, f), 'rb')
for line in fkea:
keywords.add(line.strip())
fkea.close()
fmrg = open(KEYWORDS_FILE, 'wb')
for keyword in keywords:
if keyword in stopwords:
continue
fmrg.write("%s\n" % (keyword))
fmrg.close()
if __name__ == "__main__":
main()
|
Annotate Text with Keywords
The objective is to find the 33,512 generated keywords in the combined training and testing document set, and convert each document to its equivalent bag of keywords. I had some code that wrapped Lingpipe's ExactDictionaryChunker, so I wrote a simple Scala client to load the keywords into it, and run each of our documents against it. The code transforms each file from a sequence of words to a sequence of keyword (single or multi-word) tokens.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | // Source: src/main/scala/com/mycompany/scalcium/keyextract/BagOfKeywords.scala
package com.mycompany.scalcium.keyextract
import java.io.File
import java.io.FileWriter
import java.io.PrintWriter
import scala.Array.canBuildFrom
import scala.io.Source
import com.mycompany.scalcium.utils.DictNER
object BagOfKeywords extends App {
val keaDir = "/Users/palsujit/Projects/med_data/mtcrawler/kea"
val outDir = "/Users/palsujit/Projects/med_data/mtcrawler/kea_keys"
val mergedKeys = new File(keaDir, "merged_keys.txt")
val bok = new BagOfKeywords(mergedKeys)
val files = new File(keaDir, "train").listFiles() ++
new File(keaDir, "test").listFiles()
files.filter(file => file.getName().endsWith(".txt"))
.map(file => {
val keywords = bok.tag(file)
val outfile = new PrintWriter(new FileWriter(
new File(outDir, file.getName())), true)
outfile.println(keywords.mkString(" "))
outfile.flush()
outfile.close()
})
}
class BagOfKeywords(val dictFile: File) {
val dictNER = new DictNER(Map("keyword" -> dictFile))
def tag(f: File): List[String] = {
val source = Source.fromFile(f)
val content = (try source.mkString finally source.close)
val cleanContent = content.replaceAll("\n", " ")
.replaceAll("\\p{Punct}", " 0 ")
.replaceAll("\\s+", " ")
.toLowerCase()
val chunks = dictNER.chunk(cleanContent)
chunks.map(chunk => cleanContent.slice(chunk.start, chunk.end)
.replaceAll(" ", "_"))
}
}
|
The output of this step is a new directory with a set of new .txt files. Each file corresponds to a document in the corpus, and contains a sequence of keywords that were found in the text by the chunker. We take care that we don't match across punctuation, and multi-word keywords are joined using underscores to create a single token.
Build Bag of Keywords (BoK) Gensim Model
We then build a Bag of Keywords Gensim model with the transformed corpus. I had initially thought that there would be no need for stopword removal because of the extensive preprocessing being done already, so I started with a plain term frequency model (like CountVectorizer if you are familiar with scikit-learn). However, I changed to using TF-IDF because I noticed several high Document Frequency words in the Word Cloud in my results. I also added stopword removal and custom stopwords based on observations of high DF words on the word cloud. Here is the code for my Gensim BOK model.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | # Source: src/topicmodel/bok_model.py
# -*- coding: utf-8 -*-
import logging
import os
import gensim
def iter_docs(topdir):
for f in os.listdir(topdir):
fin = open(os.path.join(topdir, f), 'rb')
text = fin.read()
fin.close()
yield (x for x in text.split(" "))
class MyBokCorpus(object):
def __init__(self, topdir):
self.topdir = topdir
self.dictionary = gensim.corpora.Dictionary(iter_docs(topdir))
def __iter__(self):
for tokens in iter_docs(self.topdir):
yield self.dictionary.doc2bow(tokens)
logging.basicConfig(format="%(asctime)s : %(levelname)s : %(message)s",
level=logging.INFO)
BOK_DIR = "/path/to/bok/texts"
MODELS_DIR = "models"
corpus = MyBokCorpus(BOK_DIR)
tfidf = gensim.models.TfidfModel(corpus, normalize=True)
corpus_tfidf = tfidf[corpus]
corpus.dictionary.save(os.path.join(MODELS_DIR, "bok.dict"))
gensim.corpora.MmCorpus.serialize(os.path.join(MODELS_DIR, "bok.mm"),
corpus_tfidf)
|
Find Optimum Number of Topics
We need to tell Gensim's topic model the number of topics we want. Since I don't really know how many topics the document set "should" contain, I project the data to 2 dimensions using an LSI model and try different values of number of topics (k), and find the one where the third differential of inertia is minimized. The background and code has been covered in my previous post, so I will only show the results I got for this new data. Here is the plot of inertia for various values of k.

As can be seen, the optimum indicated by the code is for k=4. So we try to do K-Means clustering on this reduced 2D LSI space with k=4, and it looks like we get fairly good separation between the documents.

Build LDA Topic Model
Finally, we use the original BOK model to build an LDA Topic Model with 4 topics. The code has been slightly modified to write out the top 50 terms per topic and also output the distribution of topics over each document, so I show it here.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | # Source: src/topicmodel/lda_model.py
import logging
import os
import gensim
MODELS_DIR = "models"
NUM_TOPICS = 4
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
dictionary = gensim.corpora.Dictionary.load(os.path.join(MODELS_DIR, "bok.dict"))
corpus = gensim.corpora.MmCorpus(os.path.join(MODELS_DIR, "bok.mm"))
# Project to LDA space
lda = gensim.models.LdaModel(corpus, id2word=dictionary,
iterations=300,
num_topics=NUM_TOPICS)
ftt = open(os.path.join(MODELS_DIR, "topic_terms.csv"), 'wb')
for topic_id in range(NUM_TOPICS):
term_probs = lda.show_topic(topic_id, topn=50)
for prob, term in term_probs:
ftt.write("%d\t%s\t%.3f\n" % (topic_id, term.replace("_", " "), prob))
ftt.close()
fdt = open(os.path.join(MODELS_DIR, "doc_topics.csv"), 'wb')
for doc_id in range(len(corpus)):
docbok = corpus[doc_id]
doc_topics = lda.get_document_topics(docbok)
for topic_id, topic_prob in doc_topics:
fdt.write("%d\t%d\t%.3f\n" % (doc_id, topic_id, topic_prob))
fdt.close()
|
Since I was now writing out the p(topic|term) probabilities in my own format, I ended up changing the code to visualize it was well. Here is the code to generate the tag clouds.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | # Source: src/topicmodel/viz_topics_wordcloud.py
import matplotlib.pyplot as plt
import os
import pandas as pd
import wordcloud
MODELS_DIR = "models"
ttdf = pd.read_csv(os.path.join(MODELS_DIR, "topic_terms.csv"),
sep="\t", skiprows=0, names=["topic_id", "term", "prob"])
topics = ttdf.groupby("topic_id").groups
for topic in topics.keys():
row_ids = topics[topic]
freqs = []
for row_id in row_ids:
row = ttdf.ix[row_id]
freqs.append((row["term"], row["prob"]))
wc = wordcloud.WordCloud()
elements = wc.fit_words(freqs)
plt.figure(figsize=(5, 5))
plt.imshow(wc)
plt.axis("off")
plt.show()
|
The tag clouds below show the term distribution across our 4 topics. As can be seen, the results are much better. While there will always be some fuzziness in results from unsupervised methods, the term clusters in each topic show much clearer separation than before. For example, the one on the lower left seems connected with hospitalizations, and the one on the lower right more focused on routine exams. The two on top have to do with lab tests, but the distinction is less pronounced.
 |
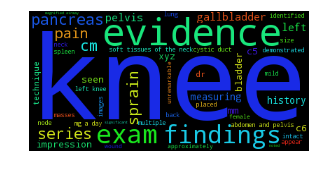 |
 |
 |
The Topic Modeling process also projects the Documents into a much smaller Topic space, where each document is a distribution over topics. This information is also returned by the LDA model in the form of p(document|topic) probabilities. As before, I write this data out from the LDA modeling step, so I wrote some code to show the probability distributions over topics for a given document.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | # Source: src/topicmodel/viz_doctopic_distrib.py
# -*- coding: utf-8 -*-
import random
import matplotlib.pyplot as plt
import pandas as pd
MODELS_DIR = "models"
NUM_TOPICS = 4
dtdf = pd.read_csv(os.path.join(MODELS_DIR, "doc_topics.csv"), sep="\t",
names=["doc_id", "topic_id", "topic_prob"],
skiprows=0)
# Choose 5 documents randomly for analysis
max_doc_id = dtdf["doc_id"].max()
doc_ids = []
for i in range(6):
doc_ids.append(int(random.random() * max_doc_id))
for doc_id in doc_ids:
filt = dtdf[dtdf["doc_id"] == doc_id]
topic_ids = filt["topic_id"].tolist()
topic_probs = filt["topic_prob"].tolist()
prob_dict = dict(zip(topic_ids, topic_probs))
ys = []
for i in range(NUM_TOPICS):
if prob_dict.has_key(i):
ys.append(prob_dict[i])
else:
ys.append(0.0)
plt.title("Document #%d" % (doc_id))
plt.ylabel("P(topic)")
plt.ylim(0.0, 1.0)
plt.xticks(range(NUM_TOPICS),
["Topic#%d" % (x) for x in range(NUM_TOPICS)])
plt.grid(True)
plt.bar(range(NUM_TOPICS), ys, align="center")
plt.show()
|
Here is the distributions for four random documents in our BOK corpus. The top two overwhelmingly belong top Topic#2 and Topic#1 respectively, whereas the bottom 2 have their topic probabilities distributed primarily across two topics.
 |
 |
 |
 |
I've been toying with the Bag of Keywords idea for a while now, its good to finally be able to try it out and see positive results. One obvious extension would be to generate keywords in case there is no training data - in such cases, one could use a controlled vocabulary against which the documents could be run (similar to the way I ran the documents against the combined set of user and KEA generated keywords), or a totally unsupervised rule-based keyword generation algorithm such as RAKE.















2 comments (moderated to prevent spam):
THanks to this clear tutorial, i have managed to generate lda model and i would like to use KEA, how did you install KEA?, i am using ubuntu 14.04 but i cant get a nice tutorial on how to install KEA,thanks
Thanks OLE LEO, glad you found it helpful. I don't think I installed KEA, just downloaded the JAR file and used it as an implicit dependency in my project (copy it to the lib directory).
Post a Comment