Continuing on from my previous blog post, where I describe the setup and some initial work to build a custom Business Intelligence (BI) tool around anonymized Medicare data, using Solr, Scala, Spring and JSTL. In this post, I will cover the remainder of the application, but unlike most of my other posts, I won't include any code. Instead, I will describe the tool from a (mostly) user-centric perspective, describing what you can do with it, and taking short detours to address the how. All the code for this project is available on GitHub, along with instructions on how to run the tool locally.
Population View
I left off last week with a single page application, the Population Demographics view. On this page, we report the distribution of members across attributes such as gender, age, ethnicity, state of residence and diseases (a member can have zero or more diseases). Each distribution is reported as a bar chart and a table in which the user is able to select one or more attribute values. Shown below is the report for the Age distribution.

Somewhat unsurprisingly, the majority of members appear to be aged between 70 and 90. Similarly, if you look at the other attributes, you will find that members are 45% Male and 55% Female, and that the majority are White (83%). California, Florida, Texas and New York have the most members (9%, 7%, 5.8% and 5.7% respectively). The most frequently observed disease is Ischemic Heart Disease (IHD) at 19%, followed by Diabetes at 17% and Congestive Heart Failure (CHF) at 13%. Interesting information perhaps (at least to lay people like me), but probably not news for people who work in population health.
But what if you are interested in the disease profile for 30-50 year old men from California compared to the national average? From the screenshots below, the younger cohort from CA (left) appears to be proportionally more prone to Depression and less prone to Cancer.
 |  |
Or imagine you wanted to know how the ethnic distribution of members from California has changed in recent years. The screenshot on the right shows the ethnic distribution of members 30-40 years old and the one on the left shows the distribution for ages 40 and up. As you can see, California has become more diverse in recent years, at least in terms of Medicare members.
 |  |
The functionality described above were implemented with Solr's Faceted Search. In all but Age, the attributes (Gender, Ethnicity, State and Disease) were the facet fields. In case of Age, we sent two initial Sort queries to find the minimum and maximum dates of birth, then partitioned the range into 10 bins, building the facets using date range queries. All the Solr code can be found in SolrService.scala.
Mortality View
Once you have selected a subpopulation in this manner, you can look at various other things. For a somewhat morbid example, you can look at the distribution of mortality rates for various diseases. Here is the distribution of ages of death for members who had some form of heart disease.

A subset of member records had a date of death populated. I found this after populating the index (populating the index took a little over a day for me), so I used Solr's partial update feature (see MortalityUpdater.scala) to compute a new age_at_death field from the birth and death dates and update this field into the index. From that point on it was two queries to get the max and min ages, partitioning the range and building a set of range facet queries on this field.
Codes View
Another way to look at a selected subpopulation is as a distribution of medical codes. Three types of codes are mentioned in the claims - the ICD-9 diagnostic codes, the ICD-9 procedure codes and the HCPCS codes. Below we show the top ICD-9 diagnostic codes for 30-60 year old Male Californians with heart disease (IHD, CHF and Stroke/TIA).
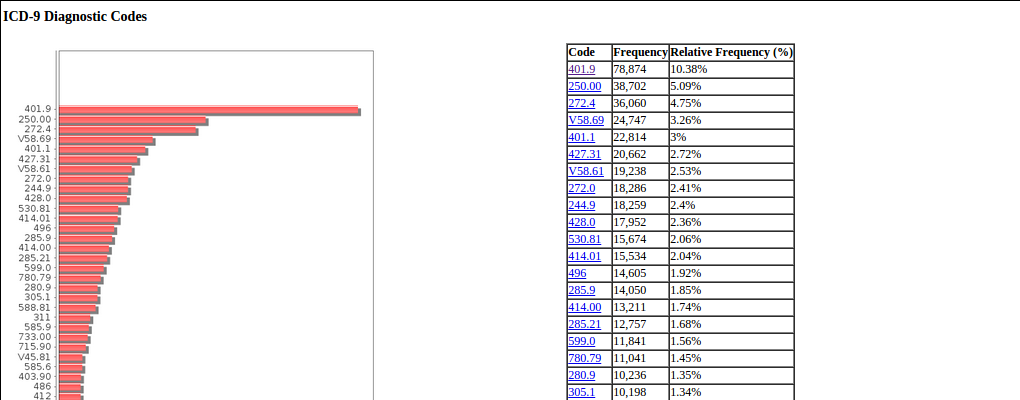
The top ICD-9 code 401.9 means Unspecified Essential Hypertension, aka High Blood Pressure, which seems to be a reasonable diagnosis for heart disease patients. It occurs 10% of the time across both types of claim - Inpatient and Outpatient. You can click on the codes to go to code lookup pages hosted by cms.gov, but if you are a company doing this for real, you would probably want to buy the code list and have the description show up beside the code without this extra step. The above results can also be filtered to show only Inpatient claims or Outpatient claims. You can also do similar analysis for the other two codes as well.
The chart and associated reports for the three codes were done using a single Solr FacetQuery with facet fields set to the three multivalued code fields, filtering by the population selection criteria.
Costs View
Similar to the Codes view, where we analyze the distribution of codes, in the costs view, we analyze the distribution of costs across claims. I decided to use the claim payment amount as the "cost" parameter. Here is the cost distribution for the same cohort as before.

As you can see, most of the claim payments are under $1,000 and a small number of much higher values. The mean is $1,090 and standard deviation is $3,750. For a more interesting look, we can drill down to the range $0-$1,000.

This shows peaks at specific amounts - I suspect that these may be standard negotiated rates, but I could be wrong. For the implementation details, once again we compute the minimum and maximum claim payment amount for the selected cohort, then split up the range into 50 buckets, then execute the corresponding 50 facet queries (its a single request) using Solr's Facet Query functionality. The descriptive statistics box with Min, Max, Mean, StdDev, etc are from Solr's StatComponent.
Correlations View
Often it is instructive to see how a pair of parameters vary with each other. Correlations are often modeled with scatter plots, here we do this using a bubble chart with actual values for categorical variables like gender, ethnicity, state and comorbidity, and ranges for continuous variables like age. Here is a plot of the incidence of specific diseases over various age ranges, across the entire dataset.

Predictably, the incidence of various diseases seems to be highest in the 70-90 age range, although some of this is also the effect of higher number of members in this age group. Other correlations charts can be built as shown in the form above the chart above. Also you can also run each on population subsets, as shown below for our cohort of 30-60 year old male Californians with heart disease.

These bubble charts are backed by Solr Pivot Queries, a form of facet query where one can specify multiple dimensions of hierarchical facets (our example does two dimensions). This is true for all the facets except the ones that involve age. Since age is computed, it cannot reside in the index and therefore cannot participate in a facet query, so we simulate this by running multiple simple facet queries based on query facets and combining the results in code.
Patients View
The Patients View shows the actual member information for members in the selected cohort (based on what we have, since the data is anonymized). We order the patients by descending order of number of transactions, since the "interesting" patients from a data analyst's point of view are the ones with more transactions. For this, I added a new field num_io to each member record that counts the number of associated Inpatient and Outpatient claims, and sorted on that field. I could probably have used Solr's Join functionality but I had already denormalized the claim records to include the member data, and that was working better for me for the cohort filtering, so I decided not to. Here is the list of members for our 30-60 year old male Californians with heart disease cohort.

You could then select a particular patient and view the claim timeline, as shown in the example below. The chart across the top represents the claim amounts as a function of time (days since start on X-axis). The highlighted rows represent Inpatient claims and the others represent Outpatient claims.

Implementation wise, I used Solr's Solr's Deep paging feature to efficiently traverse the claim records from start to end (see IOCountUpdater.scala) and the partial update feature to update the num_io field. The search part is just simple filtering and sorting, we are not even using Lucene's query functionality here. In the first case (patient list), we are sorting by num_io and in the second case (patient timeline) we are sorting by claim date.
Charts
The charts in the application are built using the JFreeChart API. The ChartService.scala provides the services to draw 3 different types of charts - barchart, line and bubble. They are called from the chart() method in the ClaimController.scala, and the actual calls to it are made from JSPs via HTML img tags.
Nothing too fancy here, of course. The only reason I bring it up is that the data to plot is passed to the chart.html call as a URL-Encoded JSON Map object. Since the data is dynamically generated from a query, it can often be quite long and exceed the default length limit for HTTP GET URLs (8k chars for Tomcat and Jetty). To get around this, the container configuration needs to be tweaked to increase this limit (somewhat arbitarily to 64k chars). This is already done for the built-in Jetty container (via the custom jetty.xml, but if you want to do this on a standalone container, here are instructions for Jetty and Tomcat.
In retrospect, I should have used a List[(String,Double)] instead of a Map[String,Double], since the latter choice needs an additional sorting step inside the ChartService, but by the time it started hurting, I had already built a few charts, so I decided to just go with it and deal with it later.
Conclusion
Thats all I have today, hope you found it interesting. While the components that make up the tool are fairly commonplace, the tool can be used to slice and dice the data in interesting ways to derive intelligence out of this data and to find subpopulations of interest. In addition, (for me) it helped me play with some of the newer features of Solr 4.x with non-text data. In any case, its almost Thanksgiving, so for those of you in the US and Canada, Happy Thanksgiving, and for those of you not in the US or Canada, here's the link to Wikipedia :-).















2 comments (moderated to prevent spam):
Thanks a lot for letting me a chance to visit your any pointers. Your article about web design is really impressed me very much. I must put a comment to your e-mail with a comment.
Thanks for the kind words Lisa, glad it helped you.
Post a Comment